In my industry at least, the high end of the margin curve is dominated by modular systems: a chassis into which cards can be added to add features, increase capacity, etc. Products at the cheaper end of the spectrum tend to be a fixed configuration, a closed box which does stuff but is not terribly expandable (often called a pizza box). The fixed configuration products sell in much larger volumes, but margins are lower.


In a pizza box system the control plane between the CPU and the chips it controls tends to be straightforward, as there is sufficient board space to route parallel busses everywhere. PCI is often used as the control interface, as most embedded CPUs contain a PCI controller and a lot of merchant silicon uses this interface.
In a chassis product, there is typically a central supervisor card (or perhaps two, for redundancy) controlling a series of line cards. There are a huge number of options for how to handle the control plane over the backplane, but they mainly fall into two categories: memory mapped and message oriented. In todays article we'll examine the big picture of control plane software for a modular chassis, and then dive into some of the details.
Memory Mapped Control Plane
A memory-mapped chassis control plane extends a bus like PCI over traces on the backplane.

To the software, all boards in the chassis appear as one enormous set of ASICs to manage.
Message Passing Control Plane
Alternately, the chassis may rely on a network running between the supervisor and line cards to handle control duties. There are PHY chips to run ethernet via PCB traces, and inexpensive switch products like the Roboswitch to fan out from the supervisor CPU out to each slot in the chassis.
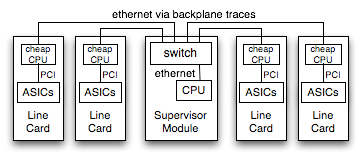
This system requires more software, as each line card runs its own image in addition to the supervisor card. The line cards receive messages from the supervisor and control their local ASICs, while the supervisor has to handle any local ASICs directly and generate messages to control the remote cards.
Programming Model
As the Gentle Reader undoubtedly already knows, the programming model for these two different system arrangements will be radically different.
| Memory mapped ASICs are mapped in as pointers | Message Passing ASICs controlled using, erm, messages. Yeah. |
volatile myHWRegisters_t *p; p = <map in the hardware> p->reset = 1; |
myHWMessage_t msg; msg.code = DO_RESET_ASIC; send(socket, &msg, sizeof(msg), 0); |
- it the same as a fixed configuration product, allowing easy code reuse
- in the message passing model you still have to write memory map code to run out on the line card CPUs, and then you have to write the messaging layer
Hot Swap Complicates Things
A big issue in the software support for a chassis is support for hot swap. Cards can be inserted or removed from the chassis at any time, while the system runs. The software needs to handle having cards come and go.
With a message passing system hotswap is fairly straightforward to handle: the software will be notified of insertion or removal events, and starts sending messages. If there is a race condition where a message is sent to a card which has just been removed, nothing terrible happens. The software needs to handle timeouts and gracefully recover from an unresponsive card, but this isn't too difficult to manage.
With a memory mapped chassis, hot insertion is relatively simple. The software is notified of an insertion event, and maps in the hardware registers. Removal is not so simple. If the software is given sufficient notice that the card is being removed, it can be cleanly unmapped and safely removed. If the card is yanked out of the chassis before the software is ready, havoc can ensue. Pointers will suddenly reference a non-existant device.
Blame the Hardware
So card removal is difficult to handle robustly in a chassis which memory-maps the line cards.

Ideally the hardware should help the software handle card removal. For example CompactPCI cards include a microswitch on the ejector lever, which signals the software of an imminent removal. The user is supposed to flip the switch and wait for an LED to light up, an indication that the card is ready to be removed. Of course, people ignore the LED and pull the card out anyway if it takes longer than 1.26 seconds... we did studies, and stuff... ok I just made that number up. Card removal is often then made into a software problem: "Just add a CLI command to deprovision the card, or something."
This makes for a reasonably nasty programming environment: to be robust you have to constantly double-check that the card is still present. Get a link up indication from one of the ports? Better check the card presence before trying to use that port, in case the linkup turns out to be the buswatcher's 0xdeadbeef pattern. Read an indication from one of the line cards that its waaaaay over temperature? Check that it is still there before you begin shutting the system down, it might just be a garbage reading.
Pragmatism is a Virtue
There is a maxim in the marketing strategy for a chassis product line: never let the customer remove the chassis from the rack - they might replace it with a competitors chassis. You can evolve the design of the line cards and other modules, but they must function in the chassis already present at the customer site. Backplane designs thus remain in production for a long time, often lasting through several generations of card designs before finally being retired. Though the Gentle Reader might have a firm preference for one control plane architecture or another, the harsh reality is that one likely has to accept whatever was designed in years ago.
So we'll spend a little time talking about the software support for the two alternatives.
Thoughts on Memory Mapped Designs
Software to control a hardware device does not automatically have to run in the kernel. There are only a few things which the kernel absolutely has to do:

- map the physical address of the device in at a virtual address
- handle interrupts and mask the hardware IRQ
- deal with DMA, as this involves physical addressing of buffers
Everything else, all of the code to initialize the devices and all of the higher level handling in response to an interrupt, can go into a user space process where it will be easier to debug and maintain. The kernel driver needs to support an mmap() entry point, allowing the process to map in the hardware registers. Once mapped, the user process can program the hardware without ever calling into the kernel again.
Thoughts on Message Passing Designs
First, an assertion: RPC is a terrible way to implement a control plane. One of the advantages of having CPUs on each card is the ability to run operations in parallel, but using remote procedure calls means the CPUs will spend a lot of their time blocked. The control plane should be structured as a FIFO of operations in flight, without having to wait for each operation to complete. If information is needed from the remote card it should be structured as a callback, not a blocking operation.
It is tempting to implement the control communications as a series of commands sent from the supervisor CPU to the line cards. Individual commands would most likely be a high level operation, requiring the line card CPU to implement a series of accesses to the hardware. The amount of CPU time it takes for the supervisor to send the command would be relatively small compared to the amount of time the line card will spend implementing the command, likely accentuated by a significantly faster CPU in the supervisor. Therefore the supervisor will be able to generate operations far faster than the line cards can handle them. In networking gear this is most visible when a link is flapping [an ethernet link being established and lost very rapidly] where commands are sent each time to reconfigure the other links. If the flapping persists, you either cause a failure by overflowing buffers in the control plane or start making the supervisor block while waiting for the line card to drain its queue. Either way, its bad.
One technique to avoid these overloads is to have the supervisor delay sending a message for a short time. If additional operations need to be done, the supervisor can discard the earlier updates and send only the most recent ones. The downside of delaying messages in this way is that it is a delay, and responsiveness suffers.
Another technique involves a somewhat more radical restructuring. The line card most likely contains various distinct bits of functionality which are mostly decoupled. Falling back to my usual example of networking gear, the configuration of each port is mostly independent of the other ports. Rather than send a message describing the changes to be made to the port, have the supervisor send a message containing the complete port state. Because each message contains a complete snapshot of the desired state of the port, the line card can freely discard older messages so long as it implements the one most recently sent.

By structuring the control messages to contain a desired state, you allow the remote card to degrade gracefully under load. Under light load it can probably handle every message the supervisor sends, while under heavier load it will be able to skip multiple updates to the same state.
Note that the ordering of updates is lost, as events can be coalesced into a different order than that in which they were sent. This coalescing scheme can only work if the various bits of state really are independent, if one state depends on an earlier update to a different state then they are not independent.
Closing Thoughts
Gack, enough about control plane implementation already.
The comments section recently converted over to Disqus, which allows threading so the Gentle Reader can reply to an earlier comment. Anonymous comments are enabled for now, though if comment spam becomes a problem that may change.