 For almost as long as it has existed, people have speculated about premium Twitter accounts as a way to monetize the service. Thus far, no such offering has appeared. Disappointment that premium accounts have never materialized was quite eloquently voiced by Suw Charman-Anderson.
For almost as long as it has existed, people have speculated about premium Twitter accounts as a way to monetize the service. Thus far, no such offering has appeared. Disappointment that premium accounts have never materialized was quite eloquently voiced by Suw Charman-Anderson.
I believe there are two fundamentally different models for premium accounts: either as power users of the free service, or as consumers of the data produced by the free users. Lets consider an example of each.
- Evernote premium accounts get an enhanced version of the free service. They can upload and index additional file types, and have added features for collaboration.
- LinkedIn premium accounts access a different type of service. They can examine everyone's connections, not just their own network. It is aimed at recruiters, salespeople, analysts, etc looking for a contact, rather than someone they personally know.
Twitter already offers paid access to its firehose of data, both directly and via gnip. A number of brand tracking, reputation measurement, and sentiment analysis tools use this firehose. Twitter is already well down the path of offering datamining services, but has yet to introduce added features for individual users. Why not? Speculating about some of the premium features which might be offered, and attempting to analyze the impact, is illuminating.
Longer search history: Twitter search goes back only a handful of days. So far as I can tell, it searches the volume of tweets which will fit into RAM across a reasonable number of servers. Searching a much larger volume of tweets would call for a different architecture, possibly involving databases on disk and a vastly larger pool of servers to handle the load.
Might Twitter offer enhanced search as a paid service, stretching back much further in time and additional search operations? That seems likely, but I would point out that even today search is not tied to your account. The search is of the public tweetstream, with no biasing for those you follow. If Twitter offers an enhanced search product it could do so as a datamining feature, not tied to a premium account.
Analytics: How many people clicked on a t.co link? How many people saw a tweet (defined as their client actually fetching it)? These features appear tied to an account and good material for premium features, but consider what people willing to pay for it are really trying to do: measure the effectiveness in spreading an idea, a brand, a celebrity name, etc. Knowing how many people saw their own tweet isn't enough: they need to know about retweets, and even quoted paraphrases of their tweet. Knowing how many times their own t.co link was clicked isn't enough, they want to know how many times any link to their URL was clicked on.
If you're trying to measure effectiveness, analyzing just one account isn't enough. The demand for analytics is primarily a datamining feature.
Group Messaging: Would twitter offer a service which allowed premium accounts to send group DMs? Meaning, send a message which can be seen by multiple participants but not be publicly searchable. Presumably this would be tied in with Twitter lists. The existence of Beluga, GroupMe, Kik, etc implies there is a demand for such a service not filled by existing tools like email.
In terms of Twitter's business, the downside of a group messaging facility is that it reduces the value of the datamining service. If taking a conversation off the record is simple, people will use it. Influencers with many contacts are perhaps even more likely to use it, and that is data which Twitter wants to be part of the zeitgeist firehose they offer.
Other features: People ask for the ability to retrieve more than the most recent 3200 of their own tweets, for higher hourly rate limits, etc. It would be quite possible to offer premium accounts with substantially higher limits. Yet consider the reaction once such accounts are available: these are features which the free accounts have, but which are artificially limited. Lifting the limit doesn't feel like a premium feature, it feels like extortion. Lifting limits isn't a good basis for a premium account, you need a strong core feature set.
A Conclusion
Offering both premium features for individual accounts and datamining services over the tweetstream is difficult, as the two are often in conflict. Individual users want to maximize their own effectiveness and, quite frankly, reserve the benefits of their use of the service to themselves by restricting access to their tweets. Removing data from the public stream reduces the value of the firehose. I suspect this is the reason Twitter has not offered such accounts, as datamining the firehose is held to be more valuable. Offering premium accounts would inevitably bring pressure to offer the features which damage the value of the firehose.
 Some time in the last several days this changed. Lists have moved one level deep in menus. Selecting "Add to list" brings up a floating window of checkboxes where list memberships can be changed.
Some time in the last several days this changed. Lists have moved one level deep in menus. Selecting "Add to list" brings up a floating window of checkboxes where list memberships can be changed. Traffic is distributed across parallel links via hashing. One or more of the MAC address, IP address, or TCP/UDP port numbers will be hashed to a index and used to select the link. All packets from the same flow will hash to the same value and choose the same link. Given a large number of flows, the distribution tends to be pretty good.
Traffic is distributed across parallel links via hashing. One or more of the MAC address, IP address, or TCP/UDP port numbers will be hashed to a index and used to select the link. All packets from the same flow will hash to the same value and choose the same link. Given a large number of flows, the distribution tends to be pretty good. The distribution doesn't react to load. If one link becomes overloaded, the load isn't redistributed to even it out. It can't be: the switch isn't keeping track of the flows it has seen and which link they should go to, it just hashes each packet as it arrives. The presence of a few very high bandwidth flows causes the load to become unbalanced.
The distribution doesn't react to load. If one link becomes overloaded, the load isn't redistributed to even it out. It can't be: the switch isn't keeping track of the flows it has seen and which link they should go to, it just hashes each packet as it arrives. The presence of a few very high bandwidth flows causes the load to become unbalanced.
 Search Twitter for the phrase
Search Twitter for the phrase 
 There is a mantra amongst network equipment vendors: never let the customer unscrew the chassis from the rack. Replace every component with upgraded equipment, but never upgrade the chassis itself. Doing so often triggers the customer to send the whole thing out for bid to multiple vendors, and you might not win. Somebody else's chassis might get slotted into the hole you left.
There is a mantra amongst network equipment vendors: never let the customer unscrew the chassis from the rack. Replace every component with upgraded equipment, but never upgrade the chassis itself. Doing so often triggers the customer to send the whole thing out for bid to multiple vendors, and you might not win. Somebody else's chassis might get slotted into the hole you left.



 Yesterday
Yesterday 


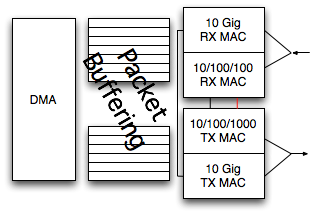 10 Gig Ethernet does not have a half duplex mode. It always operates full duplex.
10 Gig Ethernet does not have a half duplex mode. It always operates full duplex.
