Using GPL software imposes the requirement to redistribute the source code, but this requirement is routinely ignored in commercial products. That is a shame: even if one doesn't care about the goals of the free software movement, simple pragmatism would still favor providing the source code. Violating the GPL can cause Bad Things™ to happen, and compliance isn't very difficult. It is quite common for products to incorporate an almost unmodified busybox, glibc, and Linux kernel. Providing the source code for these cases is straightforward, and doesn't risk inadvertently giving away intellectual property.
Section 3 of version 2 of the GNU Public License concerns the responsibility to distribute source code along with a binary:
a) Accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
b) Accompany it with a written offer, valid for at least three years, to give any third party, for a charge no more than your cost of physically performing source distribution, a complete machine-readable copy of the corresponding source code, to be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
c) Accompany it with the information you received as to the offer to distribute corresponding source code. (This alternative is allowed only for noncommercial distribution and only if you received the program in object code or executable form with such an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.

I am not a lawyer, though I think it might be fun to play one on TV. There is a lot of detail in the GPL about the requirements for distribution of source code, and maybe I'm dense but I don't understand what half of it means. However I would contend that if you get to the point of needing to argue over the precise definition of the terms in a legal context, you've already failed.
The problem with violating the GPL is not that you'll get sued. Of course, it is quite possible you'll be sued for violating the GPL...
- Extreme Networks
- Bell Microproducts and SuperMicro
- Verizon (though the infringing product was made by Actiontec)
- Xterasys and High-Gain Antennas, LLC
- Monsoon Multimedia
- Fortinet
- D-Link
... but getting sued is not the real problem. The real problem is when a posting about misappropriation of GPL software shows up on Slashdot and LWN. The real problem is when every public-facing phone number and email address for your company becomes swamped by legions of Linux fans demanding to know when you will provide the source code. The real problem persists for years after the event, when Google searches for the name of your products turn up links about GPL violations coupled with ill-informed but damaging rants.
So we want to avoid that outcome. If you read the legal complaints filed by the Software Freedom Law Center, they follow a similar pattern:
- Someone discovers a product which incorporates GPL code such as busybox, but cannot find the source code on the company web site (probably because the company hasn't posted it).
- This person sends a request for the source code to an address they find on that website, possibly support@mycompany.com.
- This request is completely ignored or receives an unsatisfactory response.
- The person contacts SFLC, who sends a letter to the legal department of the infringing company demanding compliance with the license and that steps be taken to ensure no future infringements take place.
- SFLC also demands compensation for their legal expenses; thats how they fund their operation.
- The corporate legal team, misreading the complaint as a shakedown attempt, stonewalls the whole thing or offers some steps but refuses to pay legal costs.
- Lawsuit is filed, and the PR nightmare begins in earnest.
Keeping Bad Things From Happening
There are two points in that progression where the bad result could be averted, in steps #2 and #4. Unfortunately it is not likely you can influence either one:
- In step #2 you have no idea where that initial request for the source code will go. They might send email to the sales department, or tech support. They might call the main corporate number and chat with the answering service. The request will very likely be filtered out before it makes it to someone who would realize its significance.
- By the time the lawyers get involved in step #4, you're already toast. Corporations, particularly medium to large corporations, are routinely targeted to extract money for licensing intellectual property, business partnerships, or any number of reasons. The GPL claim will look like all the rest, and be treated in the same way.
This is a case where it is best to be proactive. One can't realistically wait until the first time someone requests the source code, too many things can go wrong and lead to the PR nightmare. Instead, Gentle Reader, it is best to post the GPL code somewhere that it can be found with little difficulty by someone looking for it, but otherwise draw little attention to itself.

When the GPL was created software was delivered via some physical medium (magnetic tapes, later supplanted by floppy disks, CDs, DVDs, etc). One was expected to include the source code on the same medium, or at least be willing to provide another tape containing the source. Nowadays many embedded systems are delivered with the software pre-installed and updates delivered via the Internet, so adding a CD of source code would add to the Cost of Goods Sold. Anything which adds COGS is probably a non-starter, so we'll move on.
It is certainly an option to tar up all of the GPL packages from the source tree and try to get it linked from the corporate website, likely controlled by someone in the marketing department. That conversation may not go the way you want:
The (hypothetical) marketing person is not being unreasonable. Ok, the last one would be unreasonable, but I thought it would be funny. Nonetheless putting GPL source code right up on the corporate website implies it is a primary focus of the corporation, when in reality it probably is just one of many tools you use in building a product. Rather than find a place on the corporate website, I advise a separate site specifically for opensource code. It needs to be something which people can easily find if they are motivated to look for it, but otherwise not draw much attention to itself. opensource.<mycompany>.com or gpl.<mycompany>.com are reasonable conventions.
Next you need a web server. Your company may already work with a web host, otherwise Google Sites is a reasonable (and free) choice. You'll need IT to set up a DNS CNAME directing opensource.<mycompany>.com to point to the new web site. If you're using Google Sites there is a Help Topic on how to do this.
The goal here is to avoid the bad result (GPL violation being posted to slashdot), not draw attention. You shouldn't spend time putting together a snazzy web site, a simple background with links to tarballs is fine. Ideally nobody will ever look at these pages.
Documentation
Lets talk about documentation. There are a number of other open source software licenses, besides the GPL. Many of them carry an "advertising clause," a requirement that "all advertising materials mentioning features or use of this software must display" an acknowledgement of the code used. The use of this clause derives from Berkeley's original license for BSD Unix, and though Berkeley has disavowed the practice there is still a great deal of open source software out there which requires it.
In practice the advertising clause results in a long appendix in the product documentation listing all of the various contributors. Honestly nobody will ever read that appendix, but nonetheless it is worth putting together. You can also include a notice that the GPL code is available for download from the following URL... so if despite your best efforts the company does get sued, you'll have something concrete to point to in defense.
Now for the hard part
The Gentle Reader may have noticed that we have not covered how to locate the GPL code used within a product. Really I'm hoping that the source tree is sufficiently organized to be able to browse the top few levels of directories and look for files named LICENSE and for copyright notices at the top of files. If it is difficult to determine whether the product contains any open source code, there is an article at Datamation which might be helpful. It discusses compliance tools, including tools which look for signatures from well-known codebases to track down more serious GPL violations.
What about the difficult case, where GPL code is being used and has been extended with proprietary code which cannot simply be posted to a website? Even if one doesn't care about the free software ethos, pragmatically this is a ticking time bomb and one that should not be ignored. I'd recommend putting up an opensource website anyway to post what you can, and working as soon as possible to disentangle the rest. Development of new features in that area of the code can be used as the lever to refactor it in a GPL-compliant way.
Update 8/2008: The Software Freedom Law Center has published a GPL compliance guide.
10/2008: Linux Hater's Redux holds up this blog post as an example of why Linux should be avoided. Okey dokey.
12/2008: Add Cisco to the list of companies sued by the SFLC over GPL issues. This time the suit was filed on behalf of the FSF for glibc, coreutils, and other core GNU components. Reactions to the news from Ars Technica and Joe Brockmeier @ ZDNET have already appeared.
5/2009: Cisco and the FSF have settled their lawsuit. Cisco will appoint a Free Software Director, make attempts to notify owners of Liksys products of their rights under the GPL, and will make a monetary contribution to the FSF.






 In 2008, I believe the instruction set is the wrong place to look for these performance gains. The overwhelming effort put into optimizing the performance of current CPU architectures represents an enormous barrier to entry for a new instruction set. Intel itself has not made much headway with
In 2008, I believe the instruction set is the wrong place to look for these performance gains. The overwhelming effort put into optimizing the performance of current CPU architectures represents an enormous barrier to entry for a new instruction set. Intel itself has not made much headway with 
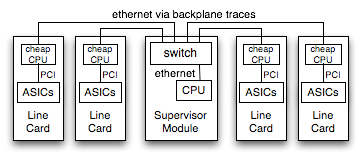
 Once we get past the pricing and volume discount models, the biggest differences between an embedded CPU and an x86 CPU designed for PCs are in the peripheral support. Consider the block diagram shown here: the CPU attaches to its Northbridge via a Front-Side Bus (*note1). The Northbridge handles the high bandwidth interfaces like PCIe and main memory. Lower speed interfaces are handled by the Southbridge, like integrated ethernet and USB. Legacy ports like RS-232 have mostly been removed from current Southbridge designs; an additional SuperIO component would be required to support them. Modern PCs have dispensed with these ports, but a serial port for the console is an expected part of most embedded networking gear.
Once we get past the pricing and volume discount models, the biggest differences between an embedded CPU and an x86 CPU designed for PCs are in the peripheral support. Consider the block diagram shown here: the CPU attaches to its Northbridge via a Front-Side Bus (*note1). The Northbridge handles the high bandwidth interfaces like PCIe and main memory. Lower speed interfaces are handled by the Southbridge, like integrated ethernet and USB. Legacy ports like RS-232 have mostly been removed from current Southbridge designs; an additional SuperIO component would be required to support them. Modern PCs have dispensed with these ports, but a serial port for the console is an expected part of most embedded networking gear.